
Additional Challenges to Detecting AI Writing
Last week, we took a look at the current state of detecting AI writing and found that, based upon the limited research that had been performed, AI detection was currently unreiable.
Shortly after I published that article, Dr. Debora Weber-Wulff, let me know about a study she and her team of researchers had published on Arxiv. Though the paper has not been peer-reviewed, it still has some interesting information that may shed light on additional challenges schools and other institutions may face when detecting AI writing.
Long-time readers of the site may remember Dr. Weber-Wulff as the researcher behind the regular analyses of plagiarism detection tools. She has earned a reputation as an excellent researcher in this space, regularly testing traditional plagiarism detection tools in a variety of scenarios.
Here, she and her researchers turn their attention to AI detection. Though the study is still fairly small in terms of papers, it looks at fourteen different systems that claim to be able to detect AI writing. Those systems include both Turnitin and PlagiarismCheck, two of the most popular commercial ones at this time, and 12 publicly available ones.
Though the findings aren’t particularly shocking, the study actually points to some potential strengths of these systems but, at the same time, some glaring weaknesses as well.
Understanding the Study
The researchers began by selecting the 14 services they would be testing and then creating a way to quantify the results that they give on a scale between a true positive (a completely correct result) and a true negative (a completely wrong result).
This was necessary because different AI detection systems display their findings in different ways. Some use a percentage method, others say that something is likely or unlikely to have been written by an AI and others rate a work on a scale of high to low risk.
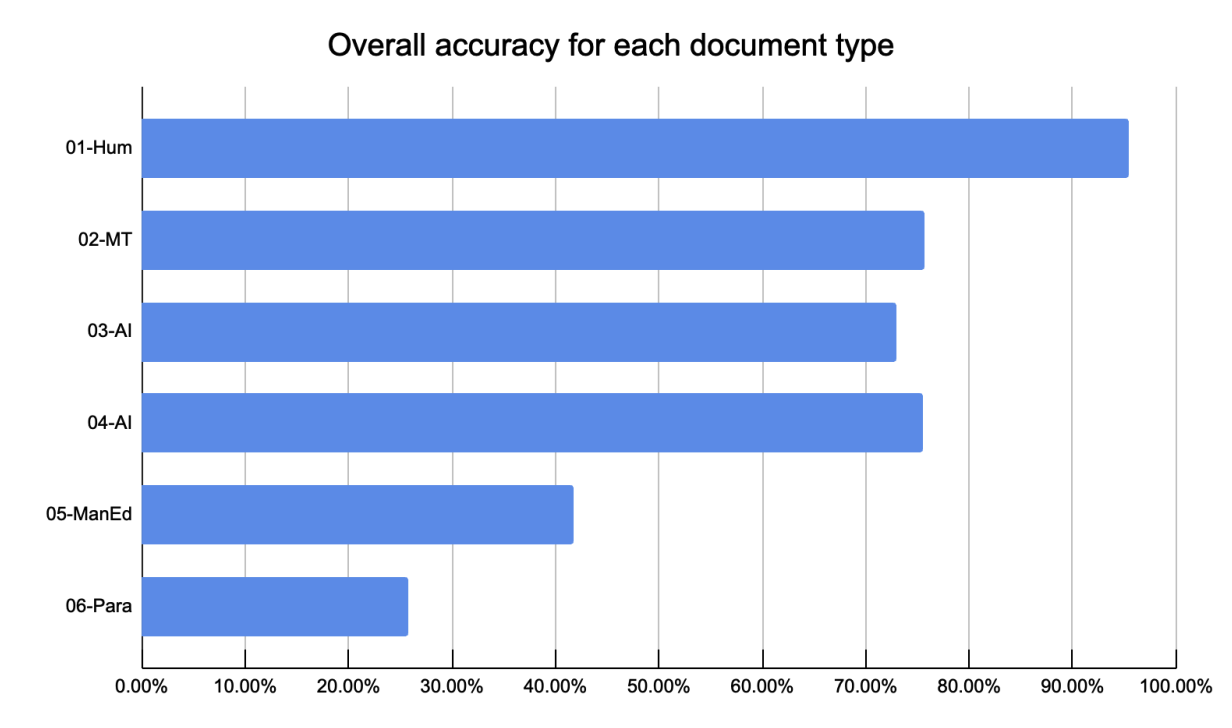
With that done, the researchers fed each of the systems 54 separate papers. Those included nine papers each across five different categories. Those categories were:
- Human written
- Human written in a non-English language and automatically translated into English
- AI-generated (two separate prompts)
- AI generated with human/manual edits
- AI-generated with subsequent AI/machine paraphrasing
After getting their findings, the team then used a series of mathematical equations to rate the accuracy of the various tools. They first looked at it from a binary standpoint, where only true positives counted, a semi-binary approach, which allowed for more nuance and a logarithmic approach, which allowed even more detail.
Though the percentages did change with each approach, the overall findings didn’t. Those findings found that, while some AI detectors were remarkably effective in certain use cases, that significant challenges remain in this space.
The Findings
Note: For this section I’m pulling the numbers from their binary approach as it’s the most clear-cut and the way most educators would likely use these tools.
Right off the bat, there was some good news here for the services that aim to detect AI generated works, in particular for Turnitin.
When looking at works that were simply human written or AI generated, most checkers did a decent job. For example, across all checks, human written works were identified as human 96% of the time. In fact, it would have been 100% if not for GPT Zero, which falsely identified three human-written works as being created by an AI. All other tools had a perfect score in that case.
There were 14 cases of false accusation when works were automatically translated into English. Six of those cases came from GPT Zero and three more from Crossplag. However, it’s difficult to say if this is truly a false accusation as, in many classrooms, this might not be a permitted way to write a paper. It comes down to the instructor, the class and the institution.
As for works generated by AI, the checkers did not do as well, but still better than many who feared. The average correctness was about 67% with the binary approach. However, that number was dragged down by several checkers, including Content at Scale, Writeful and Writer that had incredibly low detection rates.
Turnitin, for example, spotted 17 out of the 18 papers, as did GPT-2 Output Detector Demo and Check for AI. However, none had a perfect score in this category.
Where things really began to fall apart was detecting AI-generated works that were edited, either by humans or by automated paraphrasing tools.
The overall detection rate for manually edited AI-generated text was just 30%, with no checker detecting more than 5 of those cases. However, it was AI-generated text that was automatically paraphrased that faired by far the worst, with the total accuracy being merely 15% and no checker spotting more than 3.
In short, the systems faired decently well when dealing with works that were strictly either human or AI created, though still not well enough to make any final determination, but did less well with edge cases, such as human works that were automatically translated and edited AI works.
While these may be areas the tools get better at over time, as traditional plagiarism checkers did, they’re glaring weak spots right now.
That said, the sample size isn’t really enough to draw any conclusions about the accuracy of any particular plagiarism checker in any particular setting. The comparison is better served between different types of works than different checkers.
That said, if there is a “winner” it would be Turnitin, who had the highest accuracy regardless of how the score was tabulated. Likewise, Compilatio was the leader among the publicly available tools.
However, when your winner’s accuracy maxes out at 81%, that doesn’t inspire much confidence. To make matters worse, it’s a percentage that’s far too low for instructors to take action on without additional evidence.
In short, even at its best, the study’s results are bad, but the challenges it points to on the edges seem to be far worse.
Bottom Line
Based upon the issues Turnitin has faced in other testing and their own statements on the matter, I expected far worse results. Turnitin is doing significantly better than chance when dealing with works that are either exclusively AI-generated or human-written.
However, significantly better than chance is far from enough to take action against a student. Even with this small sample size, it’s clear that there are issues and other cases have shown that Turnitin is capable of making false accusations and missing AI-generated work.
And, while that’s bad, Turnitin is the “winner” of this test. All other detectors did worse, some of them, much worse.
Content at Scale, for example, failed to identify any AI-generated work. GPT Zero falsely accused 3 human papers of being AI written and still missed 4/18 AI-generated papers and 12/18 edited AI-generated papers. PlagiarismCheck, the other commercial tool, had a total accuracy of 39%, putting it in 13th place.
At its best, AI detection is nowhere near good enough for teachers to trust. At worst, in these tests, it’s less accurate than a coin flip. Combine that with the clear challenges all systems face in dealing with edited and translated works and there’s big challenges to solve, even if the companies can crack the detection of AI work, it’s plain that this space has a long way to go before its truly useful.
Want to Reuse or Republish this Content?
If you want to feature this article in your site, classroom or elsewhere, just let us know! We usually grant permission within 24 hours.