Comparing the Top Plagiarism Detection Tools
Checking on the plagiarism checker industry...
Disclosure: I am a paid blogger for Turnitin, which is mentioned in this article.
A team of nine researchers, representing 7 different countries, has published one of the most thorough analyses of the effectiveness and usefulness of the major plagiarism detection services and tools.
Their tests, conducted between November 2018 and May 2019, examined 15 separate plagiarism detection services and looked at how they handled content in 8 different languages as well as how practical they were for an academic setting.
The results highlight several relative strengths and weaknesses plagiarism detection services have across the board as well as point to differences between the services themselves.
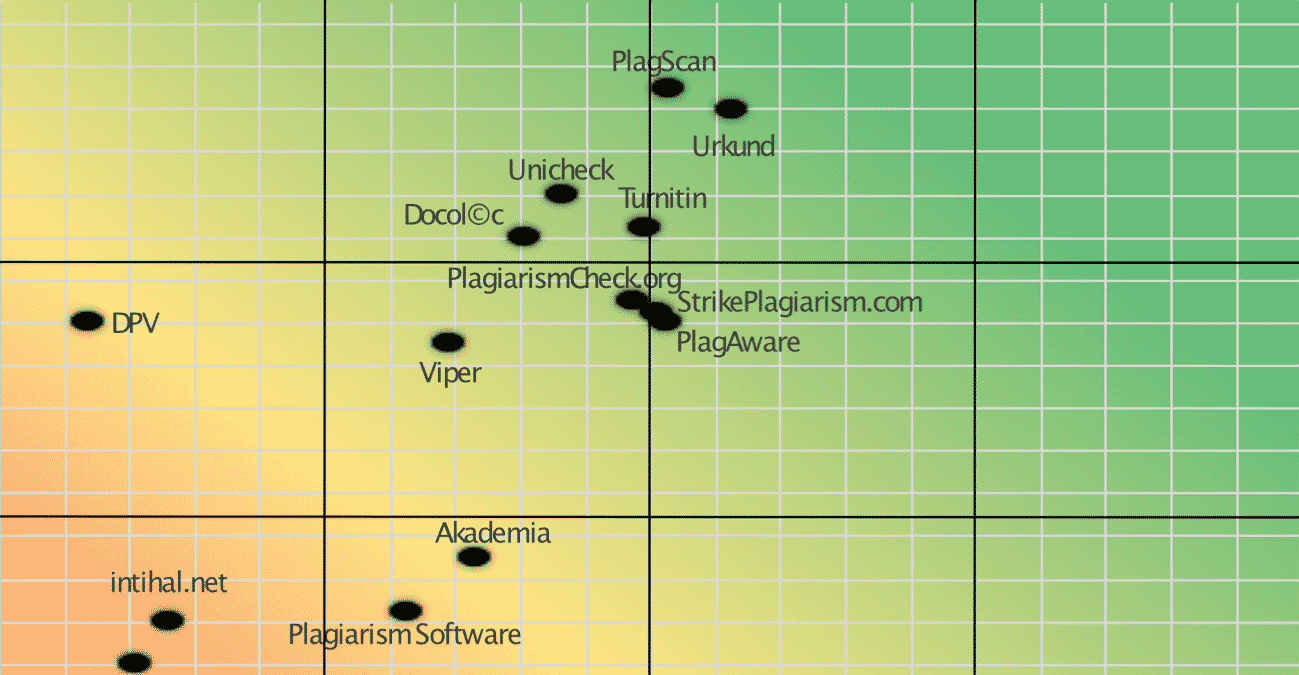
Though the study avoids making specific recommendations, it found that PlagScan, Turnitin and Urkund were the systems that were both “Useful” from a usability standpoint and “Partially Useful” from a coverage standpoint (no systems were classified as “Useful” in terms of coverage).
But the rankings themselves are, ultimately, of limited importance as the study actually says a great deal more about the industry broadly and ways that it could improve.
Testing Plagiarism Detection Tools

The team started by reaching out to some 63 vendors of plagiarism detection systems to get their cooperation with the test. Of the ones contacted, 20 responded but three had to be eliminated because they did not search internet resources and another was eliminated due to a low word count limit. Another withdrew from the test, leaving the 15 that were compared.
From there, they compared the different tools in two key areas: Coverage and Usability.
For testing coverage, they prepared a set of seven documents in eight different languages. The goal was to test the different services in how they handled a wide variety of content. This includes content copied from different sources, content with plagiarism obfuscated in different ways and content in various languages.
From there, the different plagiarism detection tools were graded on a scale of 0-5 with 5 indicating that all (or almost all) of the similarity was detected. When working with original content, the scale was flipped.
For usability, the researches established a set of criteria and simply looked at whether the tool met that criteria or not. they awarded one point if it did, a zero if it didn’t and a half point if it had the feature but it couldn’t be found without “detailed guidance” or if the researchers disagreed whether it met the criteria.
From there, the systems were tested over a six-month period between November 2018 and May 2019 and the findings were published just last month.
Global Findings

One core takeaway of the test was that no single plagiarism detection service rose to the ranking of “Useful” in the test results when looking at coverage. That would have required it to score an average of 3.75 or higher. Meanwhile, the highest system, Urkund, scored less than a 3.0.
Ultimately, none were even close.
This closely mirrors the previous work by Dr. Debora Weber-Wulff, who is one of the researchers on the team of the new study. She researched a similar conclusion in 2013 when she performed a similar study on the various plagiarism detection tools. The same also holds true in her 2011 tests.
The overall score was dragged down by weaknesses that existed largely across the board. when looking at the different tools. These include:
- Language Issues: Though top-tier checkers were able to get 3.5 and 3.3 on German and Romanic respectively. The highest for Slavic languages was 2.3 with most getting less than a 2.0.
- Translated Plagiarism: Despite years of effort being put into detecting translated plagiarism, the best tool when it came to translated plagiarism only scored a 1.1. Even paraphrased plagiarism was better detected with the highest there getting a 1.7.
- Differences in Sources: Though most seemed to do well when detecting plagiarism from Wikipedia, with Urkund even getting a perfect 5.0 for copy/paste Wikipedia plagiarism, scores across other kinds of sources varied more wildly.
All in all, the results highlighted both the strengths and weaknesses of the plagiarism detection landscape.
Looking at Individual Plagiarism Detection Tools
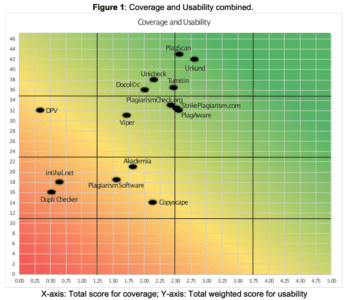
When looking at the results for the individual services, a clear trend appears.
When looking at coverage, most of the tools fell within a “pack” of sorts. Five of the tools, PlagAware, StrikePlagiarism, PlagiarismCheck, Turnitin and PlagScan, fell between 2.25 and 2.75. Only Urkund was above that (only slightly) and both Unicheck and CopyScape were slightly below it.
In the end, only three tools, Dupli Checker, Inithal and DPV, had truly awful scores compared to the others. Their averages were all below 0.75. They all earned the “Unsuited” ranking for their coverage performance.
However, it’s important to not read too deeply into the scores of any service as not all of the points will be relevant to every use case.
For example, Urkund was the winner when it came to detecting copied text in the Slavic language but Turnitin was the leader in Germanic and PlagScan in the Romanic languages. It’s much more important to pick the tool that is best for what you want it to do, not simply look at the averages and assume one is “better” than the others.
On the usability side, things were much more spread out with services ranging from a 14 (out of a maximum of 47) all the way to 43. Still, ten of the services did score above a 30 and five scored about a 35, thus giving them the title of “Useful” in this context.
Here, once again, it’s important not to read too much into the individual scores. Though CopyScape had the lowest score, 14, the usability tests were targeted at academic uses and CopyScape is not targeted for academia.
Likewise, both Turnitin and Urkund lost points for not stating their costs clearly and not having a free trial. Issues such as these may not be very important depending upon your use case.
The scores, ultimately, are averages and that average may not represent your use case. As such, it’s best not to look at the overall scores and instead make a determination of what features you need and find a service that pairs well with them.
Limitations and Considerations
The researchers, understandably, had to make decisions about what to test and how. They were forced to set up parameters and, with such parameters, comes limitations.
First, the research was intended to focus on the matching ability of the various plagiarism detection tools. As such, it looked exclusively at documents that are available to all of the systems and should be in their database.
As such, it didn’t compare content that might be exclusive to one system or another. This was of particular importance to Turnitin, which has exclusive access not only to publisher databases but their own archive of previously-submitted papers. This, however, is mitigated by the fact the study assumes that students tend to plagiarize content found on the open internet.
Second, the study is very much focused on the academic application of these tools. It doesn’t look at other potential use cases. It is focused on one type of plagiarism check, namely checking student-submitted work.
This is especially impactful in the usability section. If you are a corporate client or a law firm wanting a plagiarism analysis, your needs will be very different.
Finally, it’s important to remember that this is ultimately one set of documents. Though admittedly large and varied, the results were often close enough that a different set of documents could have produced different results.
The study mitigates this by not focusing on exact scores and instead grouping them in the “Useful”, “Partially Useful”, “Marginally Useful” and “Unsuited” categories, which means minor point changes aren’t likely to change the grouping.
Finally, as the study emphasizes (with good reason), none of the tools listed actually detect plagiarism. Though the term plagiarism detection is widely used, all of the systems detect copied text. It is up to the human using the tool to determine whether it’s plagiarism.
In short, these are not magical plagiarism detectors, but tools that aid in plagiarism detection.
Bottom Line
All in all, it’s a very well-done study and is a great tool to help schools choose a plagiarism detection system. It also highlights issues that exist in the industry and points out opportunities for improvement in the future.
If you don’t get too caught up in the averages and scores and, instead focus on the tools that meet your particular needs well, it’s a very useful study.
Though there are clear analogs to the previous work of Dr. Weber-Wufff, this new study not only updates that work but actually expands on it. The entire team did an amazing job with this study and produced an extremely thorough analysis of the current plagiarism detection landscape.
So, to end on a personal note, I want to say thank you to the entire research team for their hard work on this. It’s an amazing study well worth keeping in mind when discussing the plagiarism detection landscape.
Images from the paper are used under a Creative Commons CC-BY License.
Want to Reuse or Republish this Content?
If you want to feature this article in your site, classroom or elsewhere, just let us know! We usually grant permission within 24 hours.