DNS, SOPA, Content Blocking and More
 If you’ve been reading about Stop Online Piracy Act (SOPA), Preventing Real Online Threats to Economic Creativity and Theft of Intellectual Property act (PROTECT-IP) or the bill’s new name Enforcing and Protecting American Rights Against Sites Intent on Theft and Exploitation Act (E-PARASITES) you’ve likely been hearing a good deal about the site blocking provisions, which would enable rightsholders to get court injunctions to block access to certain websites.
If you’ve been reading about Stop Online Piracy Act (SOPA), Preventing Real Online Threats to Economic Creativity and Theft of Intellectual Property act (PROTECT-IP) or the bill’s new name Enforcing and Protecting American Rights Against Sites Intent on Theft and Exploitation Act (E-PARASITES) you’ve likely been hearing a good deal about the site blocking provisions, which would enable rightsholders to get court injunctions to block access to certain websites.
Rather than talk about the bill itself (Note: Read Terry Hart’s CopyHype and Mike Masnick’s Techdirt for pro/con analyses on the issue) I wanted to talk about the technology behind it and what it means for copyright holders both large and small.
However, to do that, we first have to take a look at what DNS is, how it works and how, likely, how these bills would work with it.
Then, and only then, can we start to figure out what the likely impact is going to be.
What is DNS?
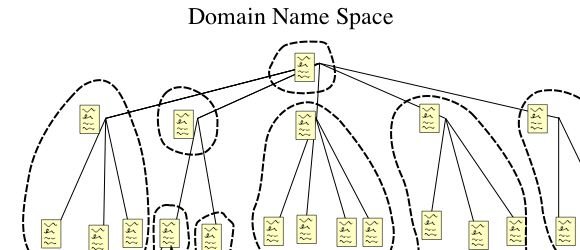
DNS stands for Domain Name System and it is a distributed system for converting the domain names we humans understand and the numbers that machines on the Web need.
Basically, every computer on the Web is identified by an IP address. Though multiple machines or sites can have the same IP, for another computer to get to yours it needs the IP address to get there. IP addresses, in the current version, are a series of four numbers from 0 to 255 separated by periods. If you go to WhatIsMyIP you’ll see what your public IP address is.
While this system is great for machines, humans would find it difficult to remember the IP address for every site they wanted to visit. DNS was created to let humans use easy-to-remember domain names (IE: plagiarismtoday.com) and translate those domains into machine-usable IP addresses.
To enable this, there are DNS servers positioned all over the world. These servers function like a telephone directory, converting the domain name into an IP address. When you type in a domain your computer hasn’t been to recently, your computer queries your designated DNS server, gets the DNS record and visits the site.
Generally, if you haven’t altered your DNS settings, you are using a DNS server provided by your ISP. That server, in turn, got its information from the root DNS servers, which sit atop of the DNS tree. Every time a change is made to a domain’s IP, the root servers are informed but it takes a while for that information to trickle down to the user-facing servers who typically cache DNS data for anywhere from 4-72 hours.
This is why, for example, when you move hosts it takes a while to show the changes on your home computer.
The main thing to remember though is that DNS functions like a phone book, listing domains and their IP addresses and converting the two for your computer. Without it, domains don’t work properly and you have to manually type in IP address information.
How DNS Blocking Works
What this has to do with the above bills is fairly simple. According to them, a rightsholder could get a court order that forces DNS providers in the U.S. to block access to a “rogue” website.
That would, most likely, work by having DNS providers simple remove the site’s domain from their list, similar to removing a name from the phonebook. Either that or the line in the database would be changed to point to the incorrect address, similar to changing the number in a phone book to direct callers elsewhere.
Similar blocking techniques are already fairly widely used. On the smallest level, many homes and businesses use similar DNS alteration techniques to block access to malware, pornography and other sites they don’t want those within visiting. OpenDNS, for example, does this for users for free.
On a grander scale, this kind of DNS filtering is part of many countries’ attempt at filtering the Web and is a key component of the Great Firewall of China.
So, while the tech has been used for good and evil in different situations, the more important question right now is “How effective would it be?”
The Effectiveness of DNS Filtering
Though DNS filtering sounds like a death blow to a website, it is anything but. After all, the site still exists and it does so at the same IP address, it just means a computer using that DNS service can’t get that IP using the domain.
This gives several options to a site that is blocked, including getting a new domain or directing visitors to use their IP. Users who want to get around such a block can do so easily as well by either switching to a different DNS service, possibly one located in another country, using the IP address directly or using a proxy (connecting to the Web via a third party computer) to bypass the DNS service.
In short, hardcore pirates would not likely be deterred, at least not greatly. A recent court order in the UK to force ISPs to block the site Newzbin 2, a Usenet scraper, has met with, at best, with mixed results as the audience of Newzbin 2 is already tech-savvy and less-than-casual in their piracy.
Casual pirates, however, might be more frustrated. Though it’s trivial to change DNS providers, a recent malware scam did it on some 4 million PCs without users knowing, it’s not something that most users know how to do or would feel comfortable doing.
Furthermore, pointing DNS to an untrusted third party can lead to other security risks as they can literally direct any domain to any server at will, raising issues of malware, identity theft and more. This makes the risks and effort higher than the reward for many casual pirates.
A lot of these workarounds could be mitigated by including IP address blocking with the DNS blocking, thus preventing anyone from accessing the IP address directly, but sites can and do change IP addresses regularly without much effort. Also, maintaining such a list would be a much greater challenge and greatly increases the risk of non-infringing sites being blocked as, at times, thousands of sites can share one IP address.
In the end, the question isn’t if someone will be able to get around these measures, it’s a matter of how many and what number of hurdles will they have to leap to make it happen.
What Does This Mean for Me?
It’s almost impossible to predict what the bill would mean for the Web if passed. There are predictions on all sides but much of the actual impact would depend on how courts approach the new law and how it is applied. That, as the Digital Millennium Copyright Act (DMCA) has showed, can be almost impossible to predict.
There are predictions on both sides ranging from sites like YouTube being blocked to a much more limited use where only a handful of extreme “rogue sites” being blocked. Those in favor of the bill claim it will only target the “worst of the worst” while those opposed to it claim it’s so broad it could impact almost any site.
Both of those predictions are theoretical until the law passes and the courts begin to wrangle with it.
One thing that is certain, however, is that smaller copyright holders probably will see no benefit from it. Even if the bill isn’t used just on the “worst of the worst”, getting a site blocked still requires a court order. Filing suit for copyright infringement is far too expensive for most smaller copyright holders, making it so that they will unlikely be able to use this bill in any way. (Note: Some versions of the bill have it so that rightsholders can force payment processors and advertisers to stop working with infringing sites on a notice-and-takedown basis rather than a court order).
In short, the most likely way a small-to-medium sized rightsholder will see anything from this bill is if they are visiting one of the site to get blocked.
Bottom Line
As hinted above, the bills have a lot more to them than just website filtering, they also include provisions for forcing payment processors, advertisers, search engines and other companies to stop doing business with or listing such sites. These provisions, in the long-run, could have a much larger impact on the Web.
One thing that is clear though is that these bills are a hot topic right now and have people lined up on both sides to either support or condemn them.
This makes it all the more important, to me, to understand how the technology would work and analyze what the likely outcomes of the tech would be.
While we can’t accurately predict how the bill would be applied, we can understand how it would work and that can give at least some insight to the legislation and its importance for the Web.
DNS Tree Image By: LionKimbro on Wikipedia – Public Domain
{kind=link}
Want to Reuse or Republish this Content?
If you want to feature this article in your site, classroom or elsewhere, just let us know! We usually grant permission within 24 hours.