Which came first the Search Engine or the Traffic?
![]() Note: This is a guest post written by Sean Harmer, a Vice President at Distil. Views or opinions expressed in this piece may or may not reflect my own. If you are interested in guest blogging for PT, please see these guidelines and contact me here.
Note: This is a guest post written by Sean Harmer, a Vice President at Distil. Views or opinions expressed in this piece may or may not reflect my own. If you are interested in guest blogging for PT, please see these guidelines and contact me here.
Have you ever wondered if the frequency of search engines crawling and indexing your website had any correlation to the number of visitors coming to your site? Or how about the opposite, do the number of visitors have any affect on search engines crawling your site? Does it even matter?
Working with client data
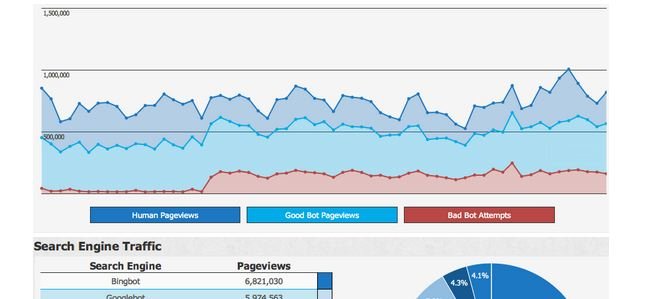
I was recently working with a client to help them better understand how good and bad web crawlers were impacting their website, when these questions came up. We looked at traffic from legitimate visitors, good web crawlers (search engines like Google, Yahoo, and Bing), and bad web crawlers, like web scrapers and data harvesters. What we found were a lot of broad patterns that didn’t move us any closer to answering “Does the frequency of search engine crawlers impact the volume of legitimate traffic?”


Side Note: JavaScript Required
It’s worth noting that most webmasters do not have visibility into good or bad web crawler activity on their sites. Have you ever wondered why Google’s web crawlers don’t show up on your Google Analytics reports? How about Yahoo’s, MSN’s, or Bings? The reason is, Google Analytics, along with a majority of other analytics tools, requires JavaScript in order to work properly. The problem is, most web crawlers, including search engines, do not use JavaScript and thus are never detected.
So back to the story. As we started digging into our client’s account data, we realized we needed to get more granular. Instead of looking at the monthly or weekly data trends, perhaps we needed to view the daily or even hourly trends. Below is a graph of one months data, broken out by day.

| Legitimate Visitors – Page Views | |
| Search Engine Crawlers – Page Views |
Observations
24 Hour Lead Time
Based on this particular client, it appears that search engine crawler activity would spike approximately 24 hours before legitimate traffic would spike. Then towards the end of the month, it was almost like the search engines were trying to learn or predict traffic patterns, as the two spikes would occur on the same day.
Mid-week Activity
One point of interest was the level of consistency search engine crawlers had week over week. In the graph below, notice that each spike in search engine activity happens around the same mid-week point each week (Wednesday or Thursday).
Consistant Activity Month Over Month
For consistency sake, we checked across multiple months to see if these patterns remained the same or changed. Although we only have a few months of data for this particular client, the charts were almost identical each month. The search engine activity would precede traffic spikes by 24-48 hours until the end of the month when they would sync up again. Although the data is too small to be conclusive, it does appear that something resets each month
Breakdown by Hour
As we dissected the data even further, we broke it down by hour and over two days found the same patterns of search engine crawlers peak, preceding the peak of legitimate traffic. In the two graphs below (representing data from 4-18-12 and 4-19-12) the search engine crawlers occurred around 9 to 10 hours prior to the legitimate traffic peak.

| Legitimate Visitors – Page Views | |
| Search Engine Crawlers – Page Views |
Figure 1: April 18, 2012 – Hourly Search Engine and Page View Data

| Legitimate Visitors – Page Views | |
| Search Engine Crawlers – Page Views |
Figure 2: April 19, 2012 – Hourly Search Engine and Page View Data
Results/Conclusion
So have we answered any of our questions?
- Is there a correlation between the frequency of search engines crawling your website and the number of visitors coming to your site?
- Does it matter?
Based on the data from this one client, it would appear that there is a direct and consistent correlation between search engine crawlers and legitimate website visitors. However, our team has pointed out the data set is still too small to be conclusive. Perhaps this data simply shows us that search engines are quicker to respond to new content or events that eventually drive legitimate traffic to the site. In other words, if the search engines were never to crawl the site, there is a chance the spike in legitimate traffic would occur regardless.
Alternatively, we must also consider the possibility that increased search engine crawling has made new or relevant content easier for legitimate traffic to find.
We admit it is very interesting to see how consistent the search engines activity has been with this client and, given the potential correlation between search engine crawlers and legitimate traffic, there appears to be a case that webmasters might be able to drive more traffic to their website, by taking steps to increase search engine activity on their site.
Side note: Three Common Ways to Increase Google’s Crawler Activity
- Create a free Google Webmasters account and upload the most recent XML version of your website sitemap.
- Keep things fresh. Work to consistently add new content to your website to ensure the search engine crawlers find something new each time they access your site. Here’s a video from Google’s principal engineer of search engine quality, Matt Cutts, that speaks to the freshness of content.
- Double and triple check to make sure every link on your website goes to a page that works. Make sure there are no errors… Search engine crawlers don’t like errors.
So does any of this matter? We do believe there is valuable insight to be gleaned from this analysis that can help webmasters, marketers, and business owners maximize legitimate traffic. At this point the data is more intended for observation and insight, versus making any concrete decisions or strategic changes. To provide more actionable analysis, our research team will continue to collect data on legitimate traffic, search engine web crawlers, and malicious web crawlers and content scrapers.
In the coming months, our research team intends write a follow-up analysis that factors in multiple industries, external events, and client activity that could also affect the frequency and total volume of traffic and crawlers.
Want to Reuse or Republish this Content?
If you want to feature this article in your site, classroom or elsewhere, just let us know! We usually grant permission within 24 hours.