
How Spam Blogs Cheat Technorati
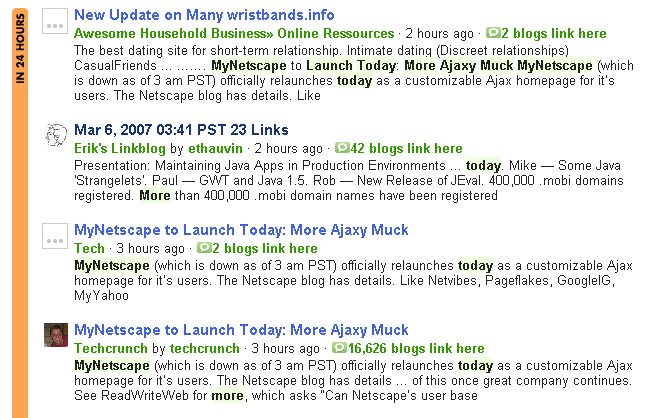 The image to the left is a screen capture from Technorati taken this morning. The bottom link is an article from the popular TechCrunch blog. The second link is a link blog that used the title from the post. The first and third link are spam blogs that are obviously scraping the TechCrunch feed.
The image to the left is a screen capture from Technorati taken this morning. The bottom link is an article from the popular TechCrunch blog. The second link is a link blog that used the title from the post. The first and third link are spam blogs that are obviously scraping the TechCrunch feed.
The screenshot was obtained by simply performing a Technorati search for the title of the TechCrunch article and it’s a trick that can work well on nearly any article on any popular blog. It seems, no matter what post you try, if a site is being regularly scraped, at least one or two of the scrapers will appear above the original site in the search results.
It is a simple screenshot that showcases a complicated problem. In the world of blogging, it is very easy for spam blogs to obtain a higher ranking in the specialized search engines that bloggers have come to rely on. Though other search engines, such as Sphere, Icerocket and Google Blogsearch are less vulnerable by default, they all can be abused if results are filtered by date.
It’s a problem that is making the flow of information tough to follow in the blogging world and is keeping legitimate bloggers from getting the exposure they deserve.
A Time-Sensitive Medium
Blogs are, for the most part, considered to be a very time-sensitive medium. It’s a nearly instantaneous conversation where posts are outdated almost the second they go up.
All things being even, newer posts are given higher precedence, they have the latest information, the most recent commentary and, if things go correctly, links to the original sources. Newer entries make it easier to follow the entire conversation and keep up to date as things evolve.
However, in the echo chamber that can be the blogging world, we’re also looking for the first “shout”. It’s important for us to know where a story started, not just so we can reward the person who does the original work, but also cut through the additional voices that come later. This is why plagiarism can be so damming in the blog community and why researches spend hours sorting through links and SERPS to find a starting point for the conversation.
If things go well, it’s possible to follow an entire conversation, from beginning to end, or rather end to beginning, using links in posts, blog search engines and blog tracking. It’s a powerful research tool that can be essential to deconstructing what happens in the lightning-fast world of blog posting and help new bloggers effectively join the conversation.
How Spam Blogs Game the System
The problem with such a time-sensitive medium is that a post, a message or a story only has a brief time at the top of the list. If you create a post targeting a specific keyword, it is at the very top once it goes up (and is picked up by the search engines) but is bumped down when something newer comes along. This can be a matter of minutes or even seconds.
Spam blogs can game this system easily. Since the original blog has to ping and send out their posts before the spam blog can pick it up, they are, most of the time, after the original post. this means that, if all goes well for them, they will be the ones at the top of the results, not the original author, and they will be the ones benefiting from whatever traffic that might bring.
So take, for example a sports blog that has a single spam blog scraping it. Every time the sports blog makes a post, it tags its posts carefully, targets good keywords and works to attract good traffic from the blog search engines. However, every time they post now, the spam blog does the exact same thing, with the exact same keywords and tags. Even if no one else posts to the keywords for hours, the original author is only at the top of the results for a few moments and that can cost them traffic and subscribers.
Though this will not likely hurt larger bloggers that barely notice traffic from the search engines, smaller ones working to get established can be greatly hurt by this. Many depend upon blog search engines to draw attention to their work and spam blogs can greatly hinder that ability.
Going Back in Time
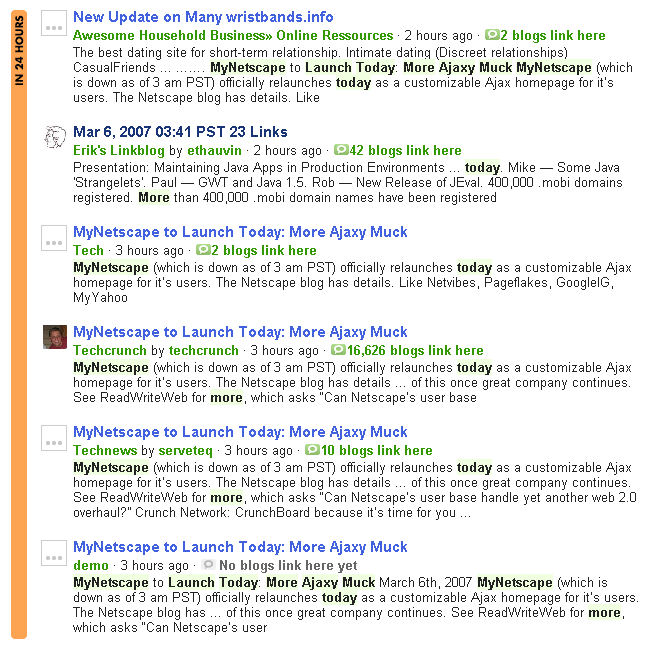 It would seem that this problem offers a consolation to those doing the original writing. Since their posts are first, they at least have proof that they are the victim, not the plagiarist.
It would seem that this problem offers a consolation to those doing the original writing. Since their posts are first, they at least have proof that they are the victim, not the plagiarist.
However, that doesn’t always work out to be the case. As the expanded screenshot to the left proves, in many cases, spam blogs also appear under the original work.
One of two things can happen that will cause a spam blogger to appear before the original site in the results.
- Technical Problems: Since location in the results is a matter of which site is spidered first and not necessarily which site is posted first, it’s easy for a technical glitch or slowdown to cause a spam blog, which posts almost immediately afterward, to actually show up first.
- Intentional Manipulation: Some spam blogs have started backdating their timestamps to appear to be earlier than they are. Though it is unclear how this affects blog search engines, at least some appear to be deceived by this.
The result is that, if you are being scraped by more than one spam blog, there is a good chance that your site is neither first nor last in the search results, but rather, much like TechCrunch, dead in the middle.
From a traffic perspective, that is the worst place to be. Neither the original author nor the latest and greatest, it is easy to get lost in the mix while spammers reap all of the benefits from your work.
Winning the Game
Much of the burden of resolving this problem is going to fall on the blog search engines themselves. Their ability to block and filter out spam blogs is critical not just to the usefulness of the information they present, but also to their bottom line. If their site becomes overloaded with junk, users will go elsewhere and their site will become irrelevant.
In that regard, other search engines have made progress. Sphere and Icerocket both, by default, place emphasis on relevance (including a combination of date, incoming links and keyword density) in choosing what posts are top. Spam blogs seem to find it much more difficult to break the top of these results. On the other hand, so do legitimate sites that are starting out.
However, it doesn’t always work perfectly .
Technorati itself offers an “authority” feature that tracks incoming links to a blog and lets searchers filter out sites with no or few incoming links. This weeds out most spam blogs as humans rarely link to them.
As potentially useful as that is, authority can also be spoofed by cross-linking spam blog networks and the authority feature doesn’t seem to work when creating RSS feeds and watchlists, two of Technorati’s most powerful and commonly-used features.
But even with these hurdles, there are still several things that bloggers can and should do to minimize the potential for this kind of problem:
- Register Your Site: Since spam bloggers almost never take the time to register their blogs with Technorati, an almost impossible process for hundreds or thousands of blogs, it makes sense to register yours to help it stand out both with the username and icon. It also shows the blog search engine who, most likely, is original.
- Establish Incoming Links: Work quickly to build incoming links to your site. Since most search engines aren’t able to distinguish between blogroll links and topical ones, exchanging links works well to get started. It only takes a few to get above the scraper sites.
- Defend Your Feed: Protect your feed against scraping. Consider using the Antileech plugin or the Uncommon Uses feature in FeedBurner to help you defend your work. Cut off or shut down sites that scrape your feed and focus on the spam blogs that Technorati and the other search engines haven’t filtered out. They are the most dangerous.
- Search Smarter: Use the tools available to help filter out potential spam blogs. Most spam blogs aren’t targeting human readers anyway, but ensuring that they don’t get those clicks is still a good step to keeping the number minimal.
Granted these are not massive steps and most are ones that are a good idea regardless of spam blogs, but they are important. After all, blogs need blog search engines, especially as they seek to get established, and the more emphasis we’re able to put on date and time, the easier the conversation is to follow.
Conclusions
Spam blogs are not going away, blog search engines are not going to be able to stop them and bloggers seeking establishment are still going to have to rely upon the blog search engines to get attention.
Solving this problem is not simply a matter of tending our own garden or the search engines stepping up, it’s going to take cooperation from everyone, search engines, bloggers, hosts, readers and advertisers.
In order to preserve the democracy that blogging is supposed to be, we need to prevent spam blogs from stuffing the virtual ballot box. It’s supposed to be a place where everyone can have a voice, instead, it is rapidly becoming a place where new voices are drowned out by junk.
This problem goes beyond just copyright issues and search engine accuracy and into the very reasons we write on the Web. The more barriers we put up to for new voices, the fewer we’ll get, it’s that simple.
Tags: Content Theft, Copyright, Copyright Infringement, Copyright Law, DMCA, Icerocket, Plagiarism, Scraping, Search Engine, SEO, Spam, Splogging, Splogs, Technorati, Sphere
Want to Reuse or Republish this Content?
If you want to feature this article in your site, classroom or elsewhere, just let us know! We usually grant permission within 24 hours.