
New Trend: Scraping Via Email
 Spam bloggers have no shortage of tools designed to scrape and republish your RSS feed. From full-blown spam blog generators, some of which can create thousands of blogs per hour, and simple WordPress plugins, there are countless tools designed to turn your content into spam.
Spam bloggers have no shortage of tools designed to scrape and republish your RSS feed. From full-blown spam blog generators, some of which can create thousands of blogs per hour, and simple WordPress plugins, there are countless tools designed to turn your content into spam.
However, as bloggers get smarter about these issues and make broader use of plugins such as Antileech and Copyfeed to block at least many of the RSS scrapers, spammers seek out new ways to blend in even better with legitimate RSS subscribers.
But in this game of cat and mouse, at least a few spammers seem to have taken a strange, if ineffective, detour.
But while this new trend may not go anywhere and was likely inspired as much by thriftiness as effectiveness, it may signal new tactics that could make RSS scraping harder to block and prevent.
Splogging By Email
The idea is fairly simple. Most blogging platforms, including free ones such as Blogspot, include a “blog by email” address that allows you to email your posts to a secret account and have them posted to your site. It is a great way to to post quick blog entries when you only have access to your email or otherwise don’t want to log in.
Last year, I reported on a then-new type of spam blog that was taking advantage of these email addresses and forwarding Google Alert emails to them as a means of converting the alert emails into short, keyword-rich blog posts for a spam blog. But while that process was interesting, some spammers have started to take this technique to the next level and use it for effective RSS scraping.
The technique goes something like this:
- Create a blog at any free service.
- Activate the blog-via-email address.
- Select the feed or feeds you want to scrape.
- Subscribe to the feeds using any number of RSS-to-Email services.
- Point the emails to the email address above.
- Let the posts roll in.
The end result is that, everytime the blogger posts a new entry to their site, the entry is emailed, within miinutes, for publication in the splog. Though it is not a traditional RSS scraper, which functions more like a traditional RSS reader, it is a stunningly effective and breathtakingly simple approach to getting content out of one site’s RSS and into a spam blog, all without using any external software.
It is easy to see why spammers might be drawn to this technique and even easier to see why bloggers may need to worry about it.
Wolf in Sheep’s Clothing
The problem with this technique is that RSS-to-Email services are widely viewed as a legitimate means of subscribing to a feed. Many sites, including this one, actively promote the ability for users to get the feed via email and encourage such subscriptions and use.
This makes the banning of such services, either via a plugin such as Antileech, which detects user agents, or IP address completely impossible. Any attempt to ban the scraper would also result in the banning of many legitimate readers.
It is a classic example of a wolf in sheep’s clothing. By using a tool commonly used by regular readers, scrapers are able to better blend in and avoid getting stopped.
Fortunately though, this technique does not appear to be one that is going to become widespread. Though some spam bloggers have clearly taken to it, the problems associated with it far outweigh the benefits when you look at it from the spammer’s viewpoint.
Severe Limitations
The biggest problem with this method is that, when you look at the process over the course of thousands of spam blogs, it becomes far too time consuming to be practical.
To use this, one would have to set up the spam blog’s email address, subscribe to the feed via a third-party service, confirm the description, delete the confirmation “post” from the spam blog and then hope the system works.
While many of these steps could be automated, they are all unnecessary when you just set up the traditional blog scraping applications. The time and money saved by not purchasing and setting up traditional scraping software is quickly lost in the time spent creating just a handful of spam blogs using the email technique.
However, an equally large problem is that the resulting blog postings often appear hopelessly mangled and are easily spotted as being poor scrapes.
First, most RSS-to-Email services alter the subject line of the email, something that appears in the title of the post, and they also provide footers to each email with information about the service and the subscription, something that appears in the body.
Furthermore, given the poor formatting most Blog-via-Email accounts provide, the posts themselves are often mangled with formatting completely ruined.
For proof of that, look at this screen shot of a post by Lorelle VanFossen scraped using SendMeRSS.
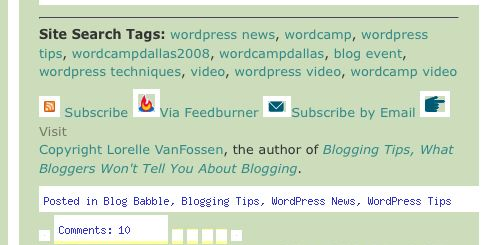
Easiest Removal Ever
However, if spammers are still drawn to this technique, believing that the ability to avoid IP and user-agent banning outweigh these issues, then it is important to also note that, despite the lack of traditional blocking means, that stopping the infringement in the future is even easier than ever.
The problem is that all legitimate RSS-to-Email services, the same as all legitimate newsletters, provide an “unsubscribe” link in the footer of the email. This link, in turn, is picked up by the blog and put into the entry.
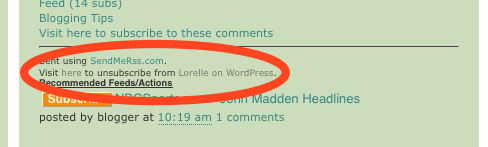
If you discover that a spam blog is scraping your content using that technique, all you have to do is click that link and you will unsubscribe the spammer from your feed. In most cases, you’ll even get a confirmation screen such as the one below.
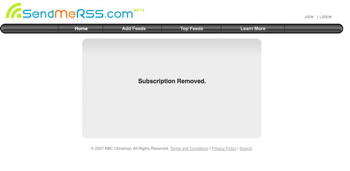
The end result is that, by clicking just one link, you put a stop to future scraping of the work and then can go back and file a DMCA notice or take other action to remove the entries that were published previously.
Taking Action
But while it is easy to to “unsubscribe” your blog from the scraper, the ideal solution would be to prevent the scraping from taking place at all.
To that end, the operators of RSS-to-Email services can help a great deal.
First and foremost, they can ensure that no accounts from the blogger.com domain are allowed to subscribe to feeds. Since, to my knowledge, no humans have that account and it is the domain used by Blogspot to post email entries, it seems logical to ban those addresses before they subscribe.
Equally importantly, they can track the emails that they send and should be able to notice when they are being “read” in places that are out of the ordinary, such as common blog hosts.
However, the most important step is to make the service reasonably difficult for an automated splogger to register for. Using common techniques, they can make it so that automating the subscription process is nearly impossible, making it a poor choice for spammers.
On that note, I spoke with Randy from SendMeRSS. He said that “SendMeRSS has a built in mechanism that automatically unsubscribes sploggers. Although they might get away with this for brief periods of time, the mechanism will eventually unsubscribe them.”
However, in Lorelle’s case, the spam blogger had been scraping the feed for nearly two weeks and had already grabbed almost a dozen entries before we removed it.
It remains unclear how long it takes for the system to kick in and kill the subscription. More importantly though, it underlies the need for bloggers to be vigilant when dealing with their own content.
Conclusions
Though this particular technique isn’t likely to become a major threat, it is only a matter of time before other methods enable the scrapers to hide among the legitimate readers.
You can already re-syndicate content feed from you Google Reader, use any number of feed combination programs to pull several feeds into one or use FeedBurner to create an all-new feed from an original. Any of these techniques could be used to produce spam blogs that are impossible to ban by traditional techniques.
The good news is that we are a long way from seeing these techniques exploited in any big way. The reason is that the extra effort that would be required to take advantage of them is not currently justified. At the moment, there are too few bloggers with the means, ability and desire to actively deal with this issue.
As long as so few people are actively thwarting the scrapers, those of us with an interest in preventing scraping will have an easier time doing so. However, as more and more Webmasters start to address these issues, our methods will have to evolve as the scrapers will inevitably alter their approach to match us.
Want to Reuse or Republish this Content?
If you want to feature this article in your site, classroom or elsewhere, just let us know! We usually grant permission within 24 hours.