
How Plagiarism Detection Works
Peek inside the black box...
 Plagiarism detection, to put it simply, is an engineering marvel. The fact that I can take a work, often as long as a hundreds of pages, upload it to a service and find out within minutes what text in it is original or duplicative is astounding.
Plagiarism detection, to put it simply, is an engineering marvel. The fact that I can take a work, often as long as a hundreds of pages, upload it to a service and find out within minutes what text in it is original or duplicative is astounding.
However, for most people, even those who use it regularly, plagiarism detection is something of a black box. Paper goes in, report comes out and what happens behind the scenes is unclear.
That, in turn, is largely by design. Plagiarism detection companies do not share their “secret sauce” and closely guard the specifics of how their products work. This is understandable not only for competitive reasons but because such openness could expose weaknesses in their specific approach.
But the truth is that most plagiarism detection systems work through a small number of methods. While one detection system can use one or a combination of methods to work or tweak the specifics of one of the methods to their advantage, they all, most likely, use some combination of these approaches.
On that note, let’s take a look at the approaches, their advantages/disadvantages and why a system might choose one over another.
Note: Because of the nature of this topic, this will be a very brief overview without a lot of details though I will ink to various papers that provide a more in-depth view for those who want it.
The Challenge Every System Must Solve
 In order for a plagiarism detection system to be considered effective. It must solve three separate problems:
In order for a plagiarism detection system to be considered effective. It must solve three separate problems:
- It Must Be Fast: If a plagiarism detection system takes days, weeks, months or years to return results, it’s useless. Results are needed in minutes or seconds. The longest I’ve waited is a few hours for an analysis of a multi-thousand page website for a consulting project. If a single document takes too long to analyze, the system is useless.
- It Must Be Cost-Efficient: If speeding up a check requiring throwing insane amounts of computing power, it’s worthless because the cost in executing it would be prohibitive. Even the most expensive services need to keep their costs per-check down, meaning that a check must be resource-efficient to be effective.
- It Must Be Accurate: This one is obvious, if a check is to be effective it must be accurate. That means both that it has to be able to analyze a large number of documents (a check that misses many matches due to a limited library is useless) and it must it must limit false positives and false negatives within that library to be useful.
The magnitude of the challenge should be clear and it’s obvious why many plagiarism checkers launched, despite starting with the best of intentions, fail miserably.
The real trick, however, is the balancing act between the three. It’s possible, for example, to create a system with incredible accuracy and is incredibly fast, but it would also be cost-prohibitive. Likewise, a system that is extremely fast and cost-efficiently will, almost certainly, be incredibly inaccurate.
However, the same balance isn’t right for all checks or systems. Sometimes the emphasis needs to be on lower cost and there can be a sacrifice on accuracy to get it. Other times, you need that accuracy, but maybe you can afford to pay for it.
But now that we’ve looked at the balancing act that all plagiarism detection systems much make, here’s a look at some of the ways they solve it.
Fingerprinting
 Fingerprinting is by far the most powerful tool in the arsenal of originality detection. It is what makes it possible to check large documents against libraries of millions of other documents.
Fingerprinting is by far the most powerful tool in the arsenal of originality detection. It is what makes it possible to check large documents against libraries of millions of other documents.
Fingerprinting works many different ways, even when just looking at plagiarism detection, but the principle is always the same. Using a complex mathematical process, you take a lengthy work, such as a file, a lot of text or something else, and convert it into a unique string, known as a fingerprint.
You see fingerprinting being used on many file download sites. If you go to download a large file, such as Mint Linux, you are given an MD5 fingerprint (though, in this case, it’s technically called a hash). Basically, this converts a 1.5 GB download, into a 32 character fingerprint that can determine the integrity of the file.
The idea is that, once you finish your download (either directly or through BitTorrent) you then run the same algorithm over your copy of the file that they did and, as long as the two files are identical, you should have the same fingerprint. If the fingerprints don’t match, you either have a bad download or it was tampered with somewhere along the way.
But where MD5 fingerprinting is useful for determining whether two files are exactly identical, the fingerprinting done by plagiarism detection systems is much more granular. Where an MD5 hash is a single string, a string for a plagiarism detection system has many substrings, sometimes referred to as minutiae.
The effect here is simple. The more substrings, the more granularity and the more accuracy in the detection but the more processing power it takes to do the checks.
The size of these substrings can range from just a few characters to many words in length. They can also look at individual characters, words, the number of letters in words or even the punctuation.
However, in all cases, the advantage is obvious. It takes far less resources to compare two fingerprints than two original works. Using fingerprinting, plagiarism detection tools can look and see if two works have enough similarity to warrant a closer look and, by adjusting the granularity of the fingerprints, can trade accuracy for speed as needed.
Couple that with algorithms that can determine not only when fingerprints match, but when they are very similar and these fingerprints can be very accurate with a minimal amount of computing resources spent.
All in all, it’s a powerful technique and one that is used by a large number of services.
String Matching
 Anyone who has read my guide on detecting plagiarism or has otherwise used Google to spot plagiarism in a work is already familiar with the concept of string matching.
Anyone who has read my guide on detecting plagiarism or has otherwise used Google to spot plagiarism in a work is already familiar with the concept of string matching.
The idea is straightforward, you take a string of text from one document, ranging from a few words to a dozen or more, and then try to find that same string in other documents. Then, repeat the process with another document or another string.
There are a slew of automated systems for doing this, each with their own approaches, but the outcome is almost always the same. String matching, since it requires comparing two full documents, requires a great deal more resources and is cost/time prohibitive by itself.
However, there are still times and places where string matching is very useful, mostly because it, under normal circumstances, is the most accurate way to detect verbatim plagiarism since there isn’t a fingerprinting layer on top of it.
As such, many systems that use fingerprinting will then turn to direct string matching when comparing suspected matches. So it will use fingerprinting when looking at the millions of documents in the database, but turn to string matching when looking at the dozen or so potential matches to find out precisely what content is overlapping.
Also, many systems rely heavily on the Google, Yahoo or Bing API to detect plagiarism and will use a form of string matching, converting a series of strings from the work that’s being tested, converting them to Google queries and then automatically compiling and filtering the results. However, the number of strings that are checked and how those strings are chosen vary from product to product and, often, from search to search.
As such, with some systems you can get very different results for searching the same text in the same product at different times.
Other Plagiarism Detection Systems
Fingerprinting and string matching are the two fundamental systems and, on the whole, they’re identical in how they work. The only difference is that fingerprinting works by converting documents into hashes for faster comparison and can add additional math to do fuzzy match comparison.
That being said, there are other approaches that are currently less used but are radically different.
- Citation Plagiarism Detection: We talked about this method in 2011, but the idea is that, for papers that have citations, plagiarized works are likely to have significant overlapping citations with their sources. This method works even if the paper is completely rewritten (and only the idea is plagiarized) and can also detect translated plagiarism. However, it can only work on papers that have citations, not on books, blog posts, etc. without them.
- Vector Space Model (Bag of Words): The idea behind the Vector Space Model is that, even if a plagiarist heavily rewrites or modifies a work, they will still use many of the same words and types of words. This model looks at the words in a paper but not the order that they are in. Then, looking at the words themselves, the parts of speech and even some common phrases, can determine the probability that two papers have strong similarity.
- Stylometry: Stylometry, sometimes called cognitive fingerprints, looks at the style of the writing. Various algorithms try to detect what makes one person’s writing style unique and then compares it to other writings. Generally has a low detection rate, but can be useful in detecting some heavily-paraphrased plagiarism.
To contrast and compare how some of the different styles work and their strengths and weaknesses, take a look at this chart drafted by Wikipedia user MrScip for the Wikipedia page on plagiarism detection (image used under a CC BY-SA 3.0 license).
{kind=link}
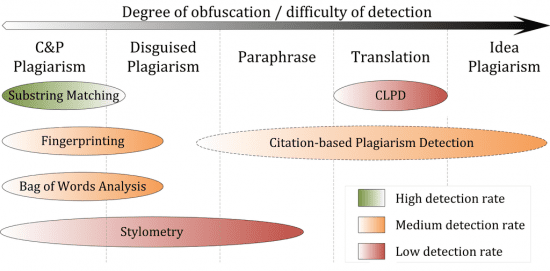
As the chart shows, every system has its strengths and weaknesses and that’s one of the reasons why many tools use a combination of approaches. However, it’s interesting to watch emerging technologies, such as stylometry, and look at how they are going to be used in plagiarism detection in the near future.
Bottom Line
In the end, there’s no one right answer to “How does plagiarism detection work?” There are many different approaches and significant variations within the individual approaches described here.
But, no matter what approach is used, what exists inside the “black box” is some pretty interesting technology and this is an area of rapid development. While detection of translated plagiarism (something I didn’t touch on here) and stylometry are fairly nascent technologies, they are rapidly improving and could become central to plagiarism detection in the future.
In short, we’re at something of a crossroads when it comes to plagiarism detection. We’re moving away from simply matching phrases and strings (either fingerprinted or verbatim) and into more artificial intelligence.
These systems are getting smarter and that’s bad news for plagiarists everywhere.
Want to Reuse or Republish this Content?
If you want to feature this article in your site, classroom or elsewhere, just let us know! We usually grant permission within 24 hours.