
Copygator: A Game Changer?
![]() Over the past few days, I have received comments from an individual claiming to use Copygator, a new service (the domain was registered on Jan. 11) that claims to “monitor your RSS feed and find where your content has been republished in the blogosphere.”
Over the past few days, I have received comments from an individual claiming to use Copygator, a new service (the domain was registered on Jan. 11) that claims to “monitor your RSS feed and find where your content has been republished in the blogosphere.”
The idea behind Copygator is that you take your site URL or your RSS feed, submit it to their site and then they monitor it for any potential matches. The site will notify you of results that it gets either via email, RSS or a color-changing badge that you can place on your site.
Though the service definitely sounds interesting, in its initial testing the results were less than impressive and I have several concerns about the service that need to be addressed before I can give it any recommendation.
Please note that this is not intended to be a thorough review of the service, just an overview of what it offers and some of my initial experiences.
The Basics
When you first visit the Copygator home page, you are given several options for how you may want to submit your content. The easiest way is to just provide either the URL of your site (and let Copygator parse your content from the autodetected feed) or submit the feed directly.
![]()
From there, the site will give you a series of options on how to subscribe for additional updates, including, as mentioned above, email, RSS and more.

And below that you see the matches that it has already found. Typically, when adding a new feed, it takes some time before any matches appear. Though the site says 10-15 minutes, in my testing it was a little bit longer, though not horribly so, at about 30 minutes.
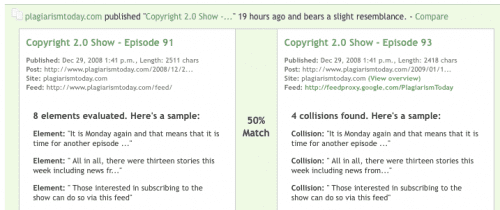
Each of the matches gives you the the option of either visiting that site’s page on Copygator, visiting the page directly or “comparing” the two works, looking at any matching text, called “collisions”, that the site has found.
Unlike other sites, including Copyscape, that display the full page and highlight relevant portions, Copygator only displays general information about the percent matching and comparisons of the similar text.
Overall, the process is pretty straightforward and easy to understand. The service does have a great deal going for it, especially if you’re a blogger that has been dealing with a large amount of scraping.
Reasons to Cheer
The good news is that Copygator is free and brain-dead easy to use. You simply submit your feed and Copygator does the rest. You even get some great choices on how you want to be notified of new matches. Though I am not sure about the color-changing button, I worry that it could be a means to spam the search engines, I could see installing it and using my WordPress theme to only display it to me when I am logged in.
The basic premise is to make this service as simple to use in every way and that permeates through the other features. For example, rather that presenting statistics about matching words or percentages, the service describes the match saying that it either “bears a slight resemblance”, “share many similar elements” or “is an exact copy”.
Though these vague descriptions may not please stat junkies or those that are dealing with very large amounts of infringement, to most bloggers, this takes a lot of the burden off figuring out which matches to look at.
In short, it is an approachable service, both in terms of price, tools and terminology. But it is far from a perfect one. There are still many elements in it that have me concerned.
Missteps and Drawbacks
The biggest problem that I have with the service is that the matching does not seem to be working correctly at this time. Though I know well that PT’s content is reused on other sites (much of it with permission), none of it seems to be picked up. Even after setting up my feed and tracking it for approximately a day, no other sites are appearing.
In fact, the only matches I am seeing right now are matches from within the site itself. Clearly, Plagiarism Today should not be showing up for its own matches (many posts, such as the podcasts, are template-based and will always bear some resemblance). The site seems to be confused since the PT has both a regular an on-server RSS (/feed) and a FeedBurner one, the former redirects to the latter (I’ve been meaning to clean this up for some time but have had other issues).
Part of the issue is a limitation with Copygator where it can only parse content in RSS feeds. It can only find matches on content found in one feed against content found in others. If the matched content does not appear in a site’s RSS feed or that blog is not among the 2 million feeds being monitored right now (in 2005 there was already an estimated 60 million blogs), it isn’t going to show up as a match.
As a result, much like Tineye, the results of the matches are very incomplete. However, the service is new and it may grow and become more valuable in the coming weeks and months. The bad news is that it has a long way to go.
Some Personal Problems
Usually, when doing write ups and reviews about new products, I do not mention any personal issues that I have with the service. However, this is a rare case where those personal issues may reflect on the site and service.
First, in the past two days I have received two comments from “James S” regarding Copygator. The first was to a post about using Copyscape to detect derivative works and the second was on my recent post about CopyrightSpot.
The two comments were clearly creating using the same template, though the first post was clearly not a complete post and both identified James as a user of the product. However, the email address that was used to post the comments is the same email that is from the whois and only one of the comments, the second, had the name linked to Copygator.
Though I am hard pressed to call this comment spam as it was to two relevant posts and it appears that the posting was not automated, I find it to disconcerting that the operator would post comments without clearly identifying himself as the creator. I have no rule that forbids product and service creators from posting information on their sites as comments, though I prefer they contact me directly.
The other concern is that the site is connected to URLFan, a search engine and aggregator I’ve expressed concern about in the past. Though the URLFan seems to have stopped engaging in the controversial behavior (truncating articles, requiring users to visit the page to view the full content, etc.), it is a pedigree that is going to concern many.
In the end, while I am worried about these elements, I did not want them to keep me from not covering a potentially useful service and I decided it was best to present my readers with the information that I know and let them decide.
I did contact “James” via the email provided before writing this article but he has not responded as of yet. However, it has only been a few hours since the initial contact (I only learned of these issues this morning). I will update and expand this article should I hear back.
Conclusions
Copygator shows a great deal of promise but it has serious limitations that prevent it from being a very useful tool at this time. Relying on it as a main source of content theft detection would be foolish at this moment. Even putting aside my personal issues and the pedigree of this site, there are just too many limitations to trust it solely.
That being said, it is nice to see some innovation and a real focus on simplicity. If this service can improve its matching, then there could be a bright future for it. The flaw might not be that it is a bad service, but that it was launched before it was truly ready.
Still, given the history of the site and how it was promoted, there are a lot of reasons to be wary of it. I intend to do some more thorough testing with it in the coming days, which I’ll likely report on next week, but I can’t see myself relying on it unless some very difficult questions are answered.
Want to Reuse or Republish this Content?
If you want to feature this article in your site, classroom or elsewhere, just let us know! We usually grant permission within 24 hours.