
Scraping Starts from the Very First Post
Rachel Radison is a New Orleans-based mortgage broker. After seeing the difficult home-buying climate in the city following Hurricane Katrina, she decided that she could help would-be buyers with her know how.
Radison, having heard about these new Web sites called “blogs” decided to create one herself and obtained a Wordpress.com account. However, her ignorance about blogs quickly caught up with her. Shortly after her first post, she checked her feed statistics and found that a whopping eleven people had subscribed to her feed.
She then quickly learned they weren’t interested in her feed at all, just her content.
Fortunately, Rachel Radison does not exist. She is a figment of my own imagination. I created both her and her site as an experiment to see both how common scraping is and how long it would take for scrapers to find a blog.
The answer surprised even me.
Background
The idea for the experiment came from an article on A Daily Rant. There, the owner took an ongoing Wordpress.com blog and shut it down, leaving only a “this blog has been moved” post to let subscribers know. He then tracked the subscribers to the feed and found that, even after most subscribers had moved over, eighteen still remained.
The experiment was interesting but flawed. Many humans change RSS readers and often forget to unsubscribe from old feeds everywhere they’ve been. For example, I am certain there are many dead feeds in my old Rojo account. It is entirely possible that, of the readers they had prior to the shut down, eighteen were simply old, but legitimate, RSS readers continuing to check the dead feed.
However, the idea seemed valid enough, take a dead feed and monitor the traffic on it. If you can set it up so that no humans should be subscribed to the feed, you can be reasonably sure that all traffic to the feed is from bots.
So, that is exactly what I did.
The Experiment
Using an old Gmail account, I created a new Wordpress.com blog. I then gave the blog a theme and gave it a name “Rachel Radison’s Mortgage Blog”. I specifically chose mortgage a topic matter because it is both a spam-friendly keyword and it is a topic I have at least a little knowledge about after buying my new home.
In order to avoid being caught in Wordpress.com’s spam filters, I decided to write the posts myself, using my extremely limited knowledge of the subject and a large amount of fluff. After a few moments of faking my way through the first post (being sure to add a footer disclaiming the site as rubbish), I made sure that the blog was going to ping all of the usual notification services and published it.
I then returned the next day to do another post but stopped off to check the feed stats, what I saw is below:
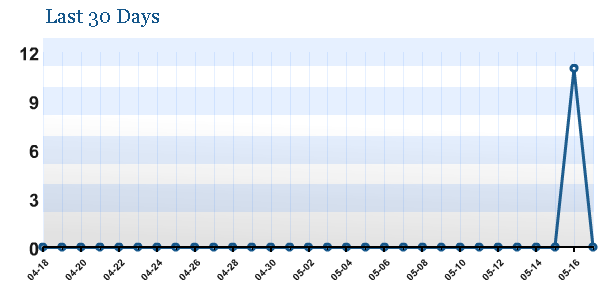
Even I was stunned by this. I had expected the feed to be scraped. But to have eleven “subscribers” after less than 24 hours was stunning.
Some of these subscribers could be easily explained. Technorati and Google both picked up the feed almost immediately. Likewise, Wordpress seems to have its own crawler. However, no others have picked it up as of this writing and that leaves at least eight “subscribers” unaccounted for.
But Wait, It Gets Worse
I posted again on the seventeenth but, due to difficulties with my move, was very late in posting on the eighteenth. However, before I posted, I checked the feed stats again, what I saw is below:
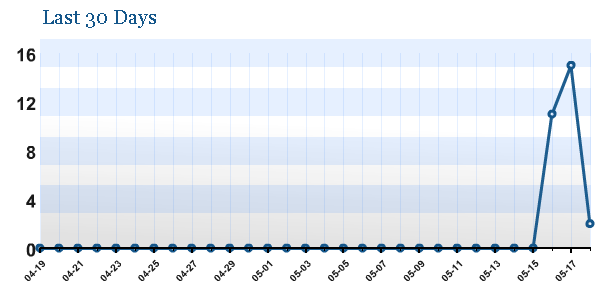
The second day had seen a whopping sixteen subscribers, though no new search engines had picked up the feed. Even more strange, day three had dropped to only three subscribers, marking an over 80% drop in subscribers.
However, shortly after I posted the third, and final, article, the subscriber count more than doubled, reaching eight. Though still a marked drop from the day before, it showed that the feed subscribers were prompted by my posting and not creation of the blog.
To test this, I then let the blog lapse for a few days. Very quickly, the feed subscriber count completely flat-lined, reaching zero.
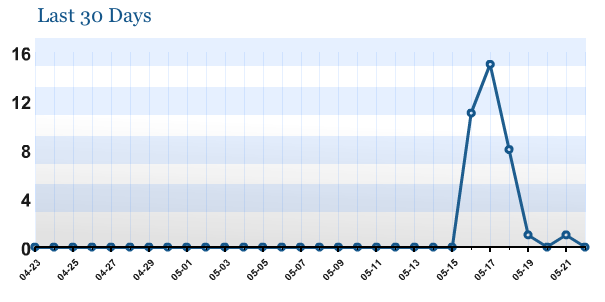
This does not follow a “human” pattern. Though feed counts rise and fall, as anyone at FeedBurner will tell you, but they do not follow this pattern. This is, almost certainly, the work of bots, both good and bad.
The outcome is pretty damming, it is obvious that there are at least some scrapers waiting for your site from the very first post and that being an unknown blogger is no protection against RSS abuse.
Problems with the Study
This isn’t to say that there aren’t problems with the study. There are several.
First and foremost, the study, by itself, means nothing. It is just one site on one service and on one topic. A more complete study would try more blogs on a variety of topics and services.
But a bigger problem is that I can not account for all of the subscribers of the feed. I have done several searches for the scraper sites but have had no luck in locating them. Odds are, it is simply too early for them to have been picked up by the search engines. Even the original site is only in Technorati and Google as of this writing.
Also, with most search engines running spam filters, it is very likely that they would catch the scraped blogs before they were indexed. In fact, I have a feeling that several have even determined that the original blog is spam, which it technically is, and refused to index it as well, thus why Icerocket, Sphere, Yahoo! and others have not added the original either.
But even if we consider all of the legitimate blog search engines that would likely be looking at the feed, it doesn’t account for all of the subscribers.
That fact is further supported by the fact that Wordpress could not identify most of the readers of the feed and, most that it did identify, were deemed “Web browsers”.
Also, as you can see in the image below, traffic to the site itself never reached anywhere near traffic to the feed (save today where I’ve been visiting the site). Most search engines, including Technorati, also visit the site when indexing the feed to ensure they get the full post (it is a way to guard against partial feeds limiting blog search engines).
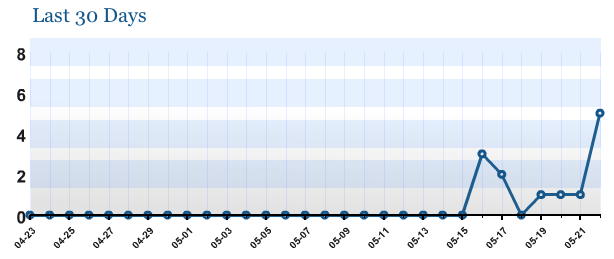
If the uses of the feed were legitimate, then traffic to the site would, initially, either meet or exceed the traffic to the feed. With no long-term subscribers that may not visit the site every day, the fact that over a dozen “subscribers” accessed the feed without accessing the site is very suspicious.
Conclusions
Though it is hard to draw any solid conclusions from this study, there are at least three things that are obvious:
- Suspicious use of a feed begins, literally, with the first post.
- Being an unknown blogger is no defense against scraping.
- Spammers are basing much of their scraping on the notification services most blogs ping. If a pinged post has a keyword they are targeting, it seems that they then visit the feed to grab the content.
What isn’t clear at this time, and likely won’t be until search engines update or drop their spam filtering, is how many of these suspicious visitors were truly scrapers. Almost certainly some were, but but some were also likely pinging services and search engines.
But if simple math is a clue and we believe that most legitimate services would also look at the site, it seems that the vast majority have less than honest intentions.
The bottom line is that something rotten is going on, it is just a matter of how rotten it is.
Want to Reuse or Republish this Content?
If you want to feature this article in your site, classroom or elsewhere, just let us know! We usually grant permission within 24 hours.