
The Two Types of Plagiarism Detection Tools
 One of the most common questions I get asked is “What is your favorite plagiarism checker?”
One of the most common questions I get asked is “What is your favorite plagiarism checker?”
My usual response is, “What am I using it for?”
The truth is that there are dozens of plagiarism checkers out there and each have their strengths and weaknesses. Most of the time, I find myself using multiple checkers in a bid to both mitigate those weakness and ensure that I find things that might be in one checker’s blind spot.
But while it’s important to know the strengths and weaknesses of your plagiarism checker of choice, it’s more important to note that plagiarism checkers are, by their very nature, very different from one another by design.
You see, when it comes to detecting plagiarism, different plagiarism checkers have different goals and are built accordingly. Using the wrong checker for your purpose might not be merely a matter of using a less-than-ideal tool, but using an outright wrong one.
As such it’s important to know the two types of plagiarism checkers so that you can help pick the one that is right for the task at hand.
Two Kinds of Plagiarism Detection
On a base level, nearly all plagiarism detection tools work the same. This is because, In reality, plagiarism detection is much more akin to “similarity detection” or “matching text detection”, tools that look for similar wording between two or more documents.
But how they perform that check and how they present their findings can differ wildly. This is because not every tool has the same purpose. One of the most important questions to ask when choosing a plagiarism checker is about the document you’re trying to scan and whether or not you already know it to be original.
That, in turn, is how we get our two types of plagiarism checking services.
- Originality Verification (Type 1): These are plagiarism detection tools that aim to take a work of unknown originality and determine whether or not it has been plagiarized.
- Infringement Detection (Type 2): These are tools that look at a known original work and find suspected misuses of it elsewhere.
While there are some plagiarism detection tools that strive to do both, such as Copyscape, most tend to focus on one or the other.
The reason is that the two types of tools have very different requirements. The most visible difference is, typically, the user interface. A tool focused on originality verification typically puts the focus on the work that’s being scanned where an infringement detection tool typically puts it on the focus on the matches.
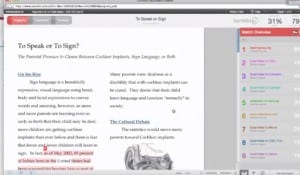
Consider, for example, the interface of Turnitin (left), which is primarily and originality verification service, compared to PlagSpotter, which is focused on infringement detection.
 |
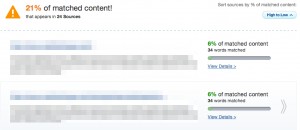 |
As you can see, Turnitin defaults to opening up the original document and highlights suspect passages where PlagSpotter, in its default interface, opens up a list of possibly infringing URLs (Note: PlagSpotter does have an “Originality Report” that more closely mirrors Turnitin’s in layout).
However, the differences generally go much deeper. An infringement detection service, for example, has little reason to worry about very small snippets and are often geared to focus on longer infringing passages that are more likely copyright infringing. Focusing on shorter ones is opening the door to excessive false positives.
On the other hand, originality verification systems definitely have a use for shorter snippets and generally seek them out because they can indicate deeper copying, including poor paraphrasing. Also, their systems aren’t designed to find every work that has matching text, but rather, just a few key examples as one instance of duplication is enough to prove something to be unoriginal.
But originality verification systems have a much bigger need for large databases and access to older works. This is because they are looking backwards from when a paper was created to see where it might have come from. Infringement detection services, on the other hand, benefit from large databases but are primarily looking forward, seeing the copies created after a work was made. That, in most cases, is a much smaller amount of work to check.
All in all, though nearly all tools that detect matching text call themselves plagiarism detection tools or plagiarism checkers, they actually function very different and some will likely not be very useful for the task at hand.
Choosing the Right Tool
When trying to choose the correct tool, it’s important to first think about what you’re trying to, whether verify the originality of an unknown work or to find copies of a known original. Whichever direction you need to go, you need to make sure that the tool you use is right for it.
Fortunately, most plagiarism detection services are pretty clear in their marketing about what they are for. If that fails, take a look at the interface and see if it’s the results or the submitted work that is most prominently featured, that typically gives you a good idea of what the service is checking for.
However, it’s important to bear in mind that there is overlap between the two types of tools and some services do try to fill both roles, usually with mixed results.
The reason for this is that, while it’s fairly easy to redesign an interface, it’s much more difficult to change the mechanics of a plagiarism detection tool to alter how and what it detects. Tools built from the ground up for one particular purpose will, generally, outperform those that were modified.
Still, that doesn’t mean that there aren’t other considerations including cost, accessibility and integration into your workflow that you need to consider. Even if a tool isn’t the best choice from a matching perspective, it may still be the best overall.
Bottom Line
When it comes down to it, plagiarism detection is tough. Though it might seem like it’s easy to match strings of text against one another, there are a million factors to consider including where you get your database from, what qualifies as a match and how to deal with duplicative results that are received from a query.
How a plagiarism checker handles these and other challenges is as much a part of what makes it succeed or fail at the task at hand and the right or wrong way to deal with these issues depends on the type of check it is trying to perform.
In short, all other things being equal, it’s much better to try and find a plagiarism checker that was built with your intended use in mind. You’ll get much better results in a much more clear fashion if you do.
Want to Reuse or Republish this Content?
If you want to feature this article in your site, classroom or elsewhere, just let us know! We usually grant permission within 24 hours.